CNNでキルミーベイベーのアレをそこそこの精度で予測する

はい、昨日から徹夜でDeep Learningで遊んでおります。
YouTubeでNNC (Neural Network Console) の実践動画を見ていくうちに「これ、アレいけるんじゃないか?」と思い立ってやってみたのが今回の企画です。
キルミーベイベーの「アレ」とは?
機械学習にある程度理解があってなおかつアニメファンという極端に狭い範囲の層の方ならもしかしたら知っているかもしれませんが、その昔、円盤(BD1巻)が686枚しか売れなかったキルミーベイベーというアニメがありました。
で、公式がそれをネタにしてそれと同じ枚数のTwitterアイコンをWebで公開しました。それが、以下です。
これが
- そこそこの量のまとまった画像データであること
- 一部を除いて登場人物の顔写真であること
- いい感じにカテゴリ分けできそうなこと
- これら全ての画像が128px四方でデータ加工の必要がないこと
といった諸々の要素が一部の技術者にウケて、度々機械学習の格好のネタになっていたのです。
私もまだDeep Learning周りの知識が浅かった時期にこの画像判別に取り組んだことがあったのですがロクな精度にならず断念していたため、せっかくなのでこの機会にリベンジしようと思いました。
データ収集
このサイトから一つひとつ手作業でDLしていてはお話にならないのでChromeの拡張機能のImage DownloaderというのをEdgeに入れて落としました。
ラベル付け
手動です。
やすな、ソーニャ、やすな&ソーニャ、あぎり、没キャラ(という名前のキャラだそうです)、それ以外という6つに分けました。それぞれ適当な半角英数のサブフォルダを切って、そこに突っ込みます。
当然データ数もそれによってまちまちで、私の場合、
| やすな | 336 |
| ソーニャ | 178 |
| やすな&ソーニャ | 41 |
| あぎり | 42 |
| 没キャラ | 10 |
| それ以外 | 79 |
になりました。
CSV作成
NNCは規定の形式のCSVファイルでないとデータを読み取ってくれないので、それを作ります。
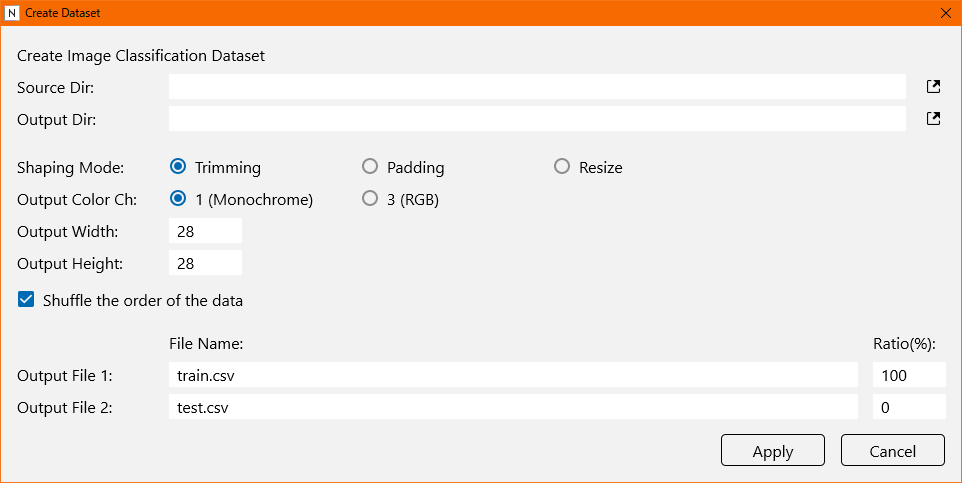
それぞれ以下のように変更しました。
| Source Dir | カテゴリ分けした画像ディレクトリ |
| Output Dir | CSVを出力するディレクトリ |
| Output Width | 128 |
| Output Height | 128 |
| Output File 1 | ファイル名は適当、Ratioは90 |
| Output File 2 | ファイル名は適当、Ratioは10 |
Output Dirに画像データの焼き直しと2つのCSVファイルが自動で生成されます。
プロジェクト作成
ニューラルネットワークをキビキビ作ります。
CNNはLeNetをベースとして手を入れました。
畳み込みユニット
畳み込みは使い回すのでユニット化します。ConvUnitという名前で新規Networkを作ります。

引数ConvMapsはConvolutionのOutMapsにバインドします。OutMapsのパラメータを *ConvMaps にすればOKです。デフォルトはPIntの16。
Main
全体図です。

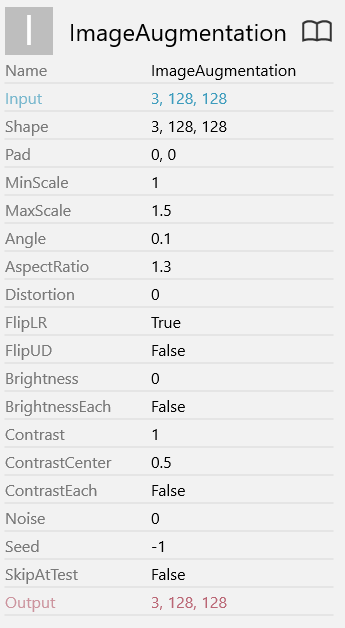
最初のImageAugmentationは画像の水増しをやってます。パラメータは以下の通り。
倍率を1~1.5倍、アス比を1.3倍、左右逆転。これらを、恐らくランダムにかけているんではないかと思います。定かじゃなくてすみません。
水増ししたら畳み込みを3回やって、Affine→ReLUを2回、Sofmaxにかけて、多クラス交差エントロピーで評価。
CUDAとはいえ8年前のマシンではこれくらいが限界ですね。。。
結 果 発 表
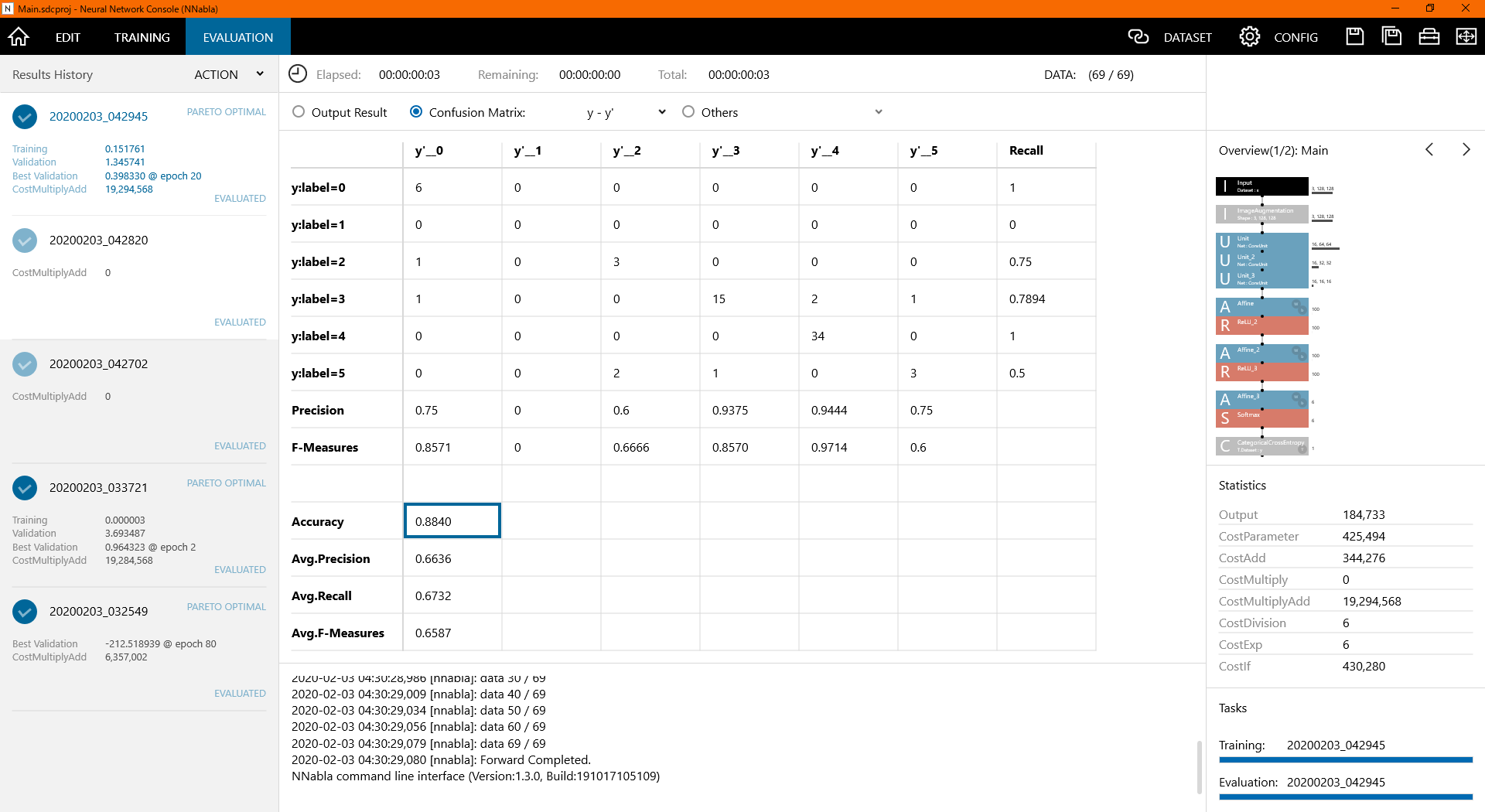
Accuracy: 0.8840
想像以上の大健闘。
ちなみにラベルですが、最も精度の良かった3と4がソーニャとやすな、次点の0と5があぎりとやすな&ソーニャ、精度60%の2がそれ以外で、1は没キャラでした。データが少なすぎて評価データに入ってませんでしたね、すみません。
とまぁこんな感じで、データ集めの大変さ、要求HWスペックの高さは依然として課題かなと思うところですが、それでも聞いてやってみるとDeep Learningってこんな簡単にできるものなのかとちょっとびっくりしました。
今後はもっと実用的な取り組みができたらなと思います。


